CTO & Technical Coach | Code That Makes Sense
Attila Fejér is a CTO, technical coach, and software crafter with 15+ years in the …

In the fast-paced world of software development, maintaining code health while delivering new features is a constant challenge. One strategy that has emerged as a crucial practice is refactoring. However, the traditional approach to refactoring often clashes with project timelines and stakeholder expectations.
In this post, we’ll explore how sustainable refactoring techniques can help strike a balance between code health and feature delivery.
Refactoring is the process of restructuring existing code without altering its external behavior. It offers numerous advantages:
Despite its benefits, refactoring can be perceived as time-consuming by managers and customers. The notion of developers spending significant time refactoring without delivering new features can raise concerns about project timelines and return on investment. This mindset often leads to resistance towards dedicating resources to refactoring efforts.
While we could try to persuade stakeholders with arguments about long-term benefits and reduced technical debt, a more practical approach exists.
Before we look at the sustainable approach, it’s worth understanding how refactoring goes wrong. Most resistance to refactoring comes from teams that have been burned by one of these patterns.
The most dangerous anti-pattern is the full rewrite. The team stops feature development for weeks (or months), locks themselves in a room, and rewrites a subsystem from scratch. The reasoning is usually: “This code is so bad that fixing it incrementally is harder than starting over.”
It rarely works. The old system had years of edge cases baked in - edge cases nobody documented. The rewrite starts clean, gets messy handling those same cases, and the team ends up in a worse position: behind on features and maintaining two half-finished systems.
Refactoring means changing the structure without changing the behavior. But if we have no tests to verify the behavior stayed the same, we’re not refactoring - we’re just editing code and hoping for the best. This is why Michael Feathers defined legacy code as “code without tests”1.
There’s another definition I like even more: legacy code is code you are afraid to change. The two are related - the fear usually comes from not having tests to catch what breaks. Without tests, every structural change is a gamble.
Sometimes developers start a refactoring and keep going. The method got cleaner, but why stop there? The class could use some work. Actually, this whole module could benefit from a redesign. Three days later, the PR has 47 changed files, and the reviewer has no idea what happened.
Gold-plating turns a focused improvement into an unbounded exploration. It makes refactoring look expensive, which fuels exactly the kind of resistance we’re trying to avoid.
A more sustainable way to refactor is to parallelize it with feature development to address time constraints. Instead of treating refactoring as a separate, standalone task, it can be integrated into the development workflow in small, incremental steps.
Consider how single-core processors handle multitasking through time-division multiplexing. Despite having only one core, these processors can execute multiple tasks concurrently by switching between them rapidly.
But there’s a catch: every context switch has a cost. The processor needs to save the current state, load the new one, and warm up the caches. If it switches too often, more time is spent switching than doing actual work.
The same applies to refactoring. If we treat it as a completely separate track - switching between “feature mode” and “refactoring mode” - the overhead adds up. We lose context, we create separate PRs that conflict with feature branches, and we give managers a visible line item to cut when the schedule gets tight.
The trick is to avoid the context switch entirely. Don’t put refactoring on a separate track. Weave it into the feature work itself.
Kent Beck put it simply: “Make the change easy, then make the easy change.”
The idea is straightforward. When we pick up a feature or bug fix, we first look at the code we need to change. If the current structure makes the change awkward, we refactor first - but only the minimum needed to make the change clean.
Let’s see what this looks like. Suppose we need to add email notifications to an order service:
class OrderService {
void placeOrder(Order order) {
// validate
if (order.getItems().isEmpty()) {
throw new IllegalArgumentException("Order must have items");
}
if (order.getCustomer() == null) {
throw new IllegalArgumentException("Order must have a customer");
}
// calculate total
double total = 0; // double for money? 😱 I know. I'd use BigDecimal in a real system, but double is simpler to understand in an example
for (Item item : order.getItems()) {
total += item.getPrice() * item.getQuantity();
if (item.getDiscount() > 0) {
total -= item.getPrice() * item.getQuantity() * item.getDiscount();
}
}
order.setTotal(total);
// save
database.save(order);
// log
logger.info("Order placed: " + order.getId());
}
}
We could just add the email sending at the end. But this method is already doing four things: validation, calculation, persistence, and logging. Adding a fifth responsibility won’t make things better.
Instead, we first refactor - extract the distinct responsibilities2:
class OrderService {
void placeOrder(Order order) {
validate(order);
calculateTotal(order);
database.save(order);
logger.info("Order placed: " + order.getId());
}
private void validate(Order order) {
if (order.getItems().isEmpty()) {
throw new IllegalArgumentException("Order must have items");
}
if (order.getCustomer() == null) {
throw new IllegalArgumentException("Order must have a customer");
}
}
private void calculateTotal(Order order) {
double total = 0;
for (Item item : order.getItems()) {
double itemTotal = item.getPrice() * item.getQuantity();
if (item.getDiscount() > 0) {
itemTotal -= itemTotal * item.getDiscount();
}
total += itemTotal;
}
order.setTotal(total);
}
}
Now placeOrder reads like a recipe. Adding email notification is trivial:
void placeOrder(Order order) {
validate(order);
calculateTotal(order);
database.save(order);
notifyCustomer(order);
logger.info("Order placed: " + order.getId());
}
The refactoring and the feature land in the same PR. Separately, neither would justify a ticket. Together, they make the codebase better and the feature cleaner3.
We don’t necessarily have to do large-scale restructuring. It’s a good start if we apply the Boy Scout Rule: leave the code better than we found it. Using this principle, we can ensure that each code modification includes a small refactor to improve the quality of the surrounding code. Over time, these incremental improvements accumulate, leading to a healthier and more maintainable codebase.

What does “a small refactor” actually mean in practice? Here are a few examples of things we can do every time we touch a file:
None of these takes more than a minute. None of them requires a separate PR or a discussion in the standup. But over weeks and months, they compound. A codebase where every developer follows the Boy Scout Rule gets measurably better with every commit.
Sometimes, a piece of code is too far gone for small improvements. A module grew organically over the years, nobody fully understands it, and every change introduces unexpected side effects. The Boy Scout Rule won’t save it, and a big-bang rewrite is too risky.
The Strangler Fig pattern - named after the tropical plants that grow around a tree until they replace it entirely - offers a middle ground. The idea is simple: build the replacement alongside the original, redirect traffic piece by piece, and remove the old code only when nothing depends on it anymore.
In practice, this usually means:
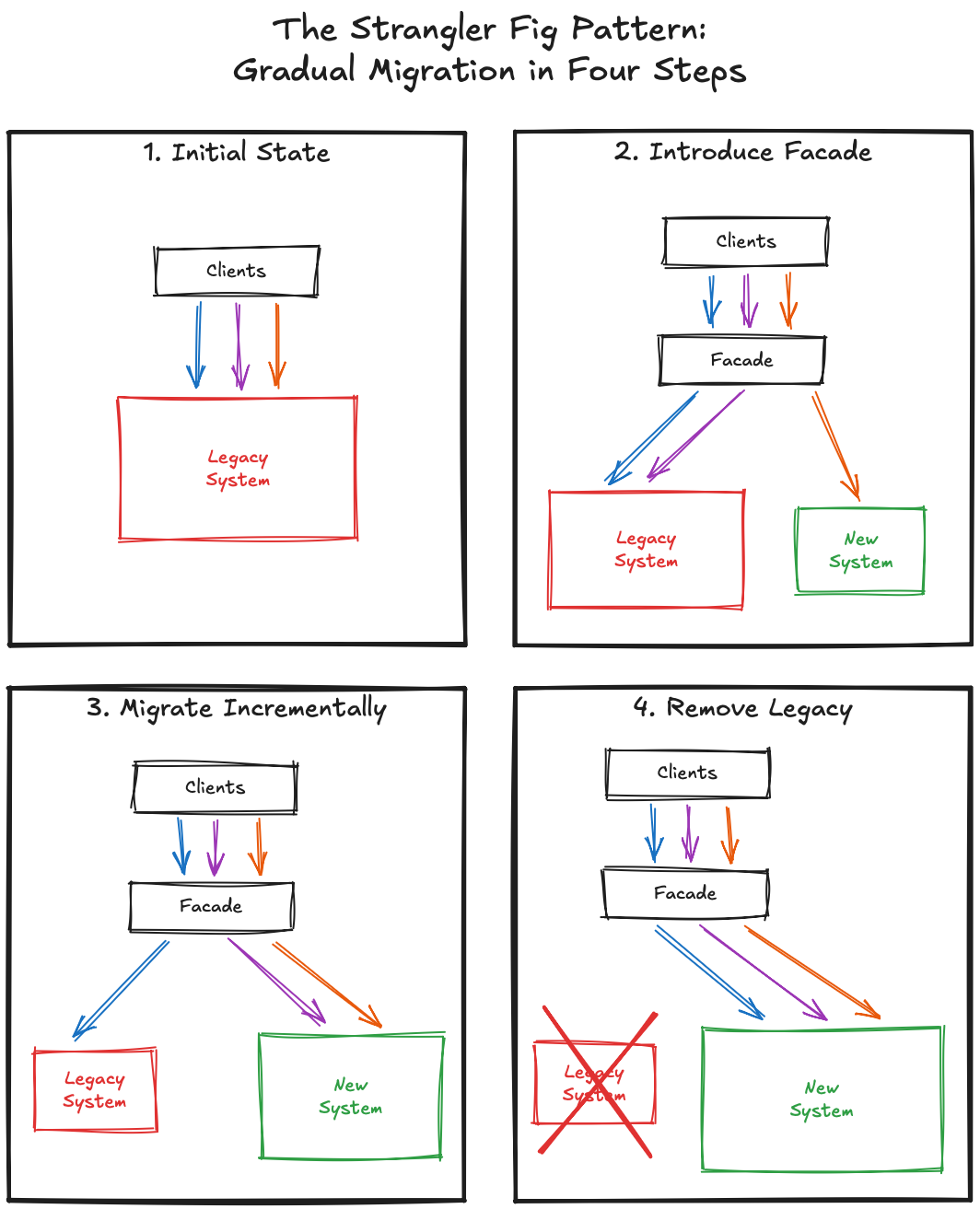
This works well for replacing legacy services, rewriting data access layers, or migrating from one framework to another. The key property is that the system works at every step. We never have a “migration weekend” where everything breaks.
The Strangler Fig is slower than a rewrite. But it ships. And it ships continuously, which means stakeholders see progress, not a black hole of effort with a promise at the end.
Here’s a pragmatic observation: if refactoring needs approval, it won’t happen. Schedules are always tight, and “improve code quality” will always lose to “ship the next feature” in a prioritization meeting.
The techniques above work precisely because they don’t require separate approval. Preparatory refactoring and the Boy Scout Rule happen inside feature work. The Strangler Fig can be framed as a gradual migration, which is easier to sell than “we need to stop and rewrite.”
A few tactics that help in practice:
Will this impact development speed? Certainly. But not the way we think. By keeping the code in a healthier state, future changes will be much faster to make. In other words, we slow down to go faster.
Martin Fowler describes this well in his concept of the “design stamina hypothesis.” Without good design, feature delivery starts fast but slows down as the codebase deteriorates. With sustained refactoring, the initial pace is slightly slower, but the curve stays flat - or even improves - over time.
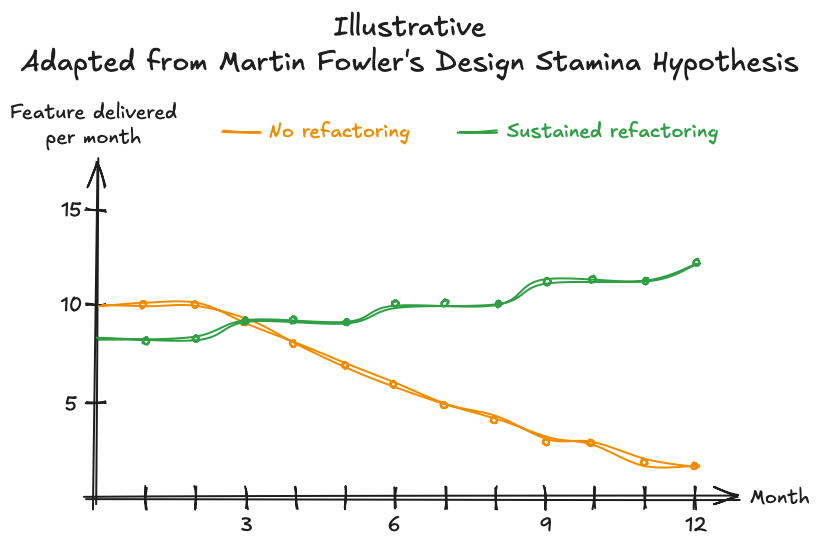
Think of it as compound interest. A 1% improvement per week doesn’t feel like much. But after a year, the codebase is unrecognizable compared to a team that stopped investing in code health. The teams I’ve worked with that consistently applied these techniques didn’t just have cleaner code - they shipped faster than the teams that “didn’t have time” to refactor.
Sustainable refactoring is not about sacrificing feature delivery for code health or vice versa. Instead, it’s about finding a balance that allows continuous improvement while meeting project requirements. Teams can effectively achieve code health and feature delivery goals by integrating refactoring into the development process and adopting parallelization strategies.
The key principles:
Refactoring is not a phase. It’s a habit. The best time to start was months ago. The second-best time is with the next feature you pick up.
Try this week: pick the next feature on your board. Before writing new code, spend 15 minutes improving the structure of the code you’ll touch - extract a method, rename a variable, remove dead code. Commit the cleanup separately, then build the feature on top. Do this for every PR this week. You’ll be surprised how quickly the habit sticks.
Media attributions:
Michael Feathers, Working Effectively with Legacy Code. His definition is deliberately provocative, but the point stands: without tests, safe structural changes are nearly impossible. ↩︎
Note how the comments have marked what needs to be extracted. That is a common sign. ↩︎
A good practice is to put the refactoring in one commit and the feature in the next. This way, the reviewer can verify the refactoring didn’t change behavior before looking at the new functionality. ↩︎

CTO & Technical Coach | Code That Makes Sense
Attila Fejér is a CTO, technical coach, and software crafter with 15+ years in the …